

Microservice architectures have firmly established themselves as a de-facto standard for building scalable and resilient distributed systems in today’s software landscape. Their rise to prominence is understandable, offering compelling advantages over traditional monoliths and the often-problematic hybrid form of the distributed monoliths. Benefits like independent deployability allowing for faster release cycles, granular scalability to handle varying loads efficiently, and so on have been covered at length. If you are interested in learning more about the potential challenges associated with transitioning from a monolith to microservices, I recommend checking out this blog post by my colleague Matthias Schrabauer at &.
However, embarking on a microservice journey is anything but a walk in the park. Architects quickly find themselves navigating a labyrinth of critical and complex decisions. How do we effectively identify customer journeys and align service boundaries accordingly, avoiding artificial splits? Where should crucial data reside, and how do we handle (eventual) consistency, or necessary co-location of data spread across multiple services? What are the right communication patterns — should we rely on old-school synchronous APIs, or go down the event-driven route and embrace approaches like event sourcing, or implement patterns like CQRS?
Navigating this maze is inherently complex, and it’s easy to take a wrong turn. A path chosen with the best of intentions can lead down a path of increasing complexity, coupling, and operational burden, accumulating technical debt with each new feature implemented. Many software engineers and architects have found themselves at a frustrating crossroads — stuck with architectural decisions that seem irreversible.
This blog post aims to be your guide within this challenging terrain. Here at &, we’ve navigated this maze ourselves in a real-world problem and encountered several of the common wrong turns — those architectural pitfalls that can harm projects. This experience taught us how to spot the tell-tale symptoms early and develop effective strategies to overcome them. Follow along as we highlight some pitfalls in an illustrative domain and share practical approaches for navigating around or recovering from them.
The Fragmented Bookstore 📚
Let’s consider an example: an online application we’ll call the “Fragmented Bookstore”. This application is a fictional web shop of my favourite bookstore, Daunt Books in Marylebone, London (as seen in the image below), selling both physical hardcover books and digital ebooks. Customers can browse the catalog, add either type of book (hardcover, ebook, or a mix) to their cart, place an order, and track the status of each item until (a) the hardcover is delivered or (b) the ebook access is granted.

Communication is handled via Kafka, a distributed event streaming platform. As illustrated in the architecture diagram below, the backend is decomposed into several key services with a single frontend:
- Order Service: Manages the shopping cart, checkout, and payment. It tracks the lifecycle state for each item (e.g., ORDER_PLACED, SHIPPED, ACCESS_GRANTED). Sends events to specialized services, and consumes their status or failure events.
- HardcoverLogistics Service: Manages physical book fulfillment (inventory, shipping) and reports back its status or issues.
- EbookProvisioning Service: Handles digital delivery (licensing, links) and reports back its status or issues.
- Frontend: Queries from and sends mutations to all three services to aggregate data and display to the user.

When designing this system, separating HardcoverLogistics and EbookProvisioning was favoured over a single complex Delivery service. This initial thinking followed common microservice reasoning, including:
- Sufficient Differences: Physical logistics (shipping, inventory) are fundamentally distinct from digital provisioning (licensing, access rights).
- Independent Evolution: Allows physical and digital logic to change and deploy separately without impacting each other.
- Limited Common Features: Core workflows differed significantly; shared aspects (like status reporting) seemed insufficient initially to justify merging.
- Implementation Autonomy: Specialized services handle the how of fulfillment independently, receiving only the what (item to process) from the Order Service.
This separation seems logical on the surface, promoting focus and independent scaling. However, as we’ll explore next, this seemingly reasonable design can lead to several challenging architectural wrong turns.
Service boundaries are misaligned with customer journeys
A frequent challenge in microservice design arises when service boundaries are drawn around technical layers, data entities, or process fragments, rather than reflecting cohesive business capabilities or complete customer journeys. Our simplified Fragmented Bookstore architecture exemplifies this, as the core capability of “fulfilling an order item” remains fragmented across services:
- The Order Service handles the initiation (checkout, payment) and, crucially, now also manages the high-level state and holds common rules/data (like stock and edition) for each item. It delegates processing via events like ProcessHardcoverEvent and ProcessEbookEvent.
- The actual execution of fulfillment is handled by specialized services based on item type:
- The HardcoverLogistics Service executes physical steps upon receiving its event.
- The EbookProvisioning Service executes digital steps upon receiving its event.
This separation, particularly bundling core order management, state tracking, and common data (like invoice address, delivery address) within the Order Service, potentially misaligns boundaries. It can fragment the “inventory management” capability away from the HardcoverLogistics service that deals with physical stock. This concentration of distinct responsibilities within the Order Service can conflict with SOLID principles like the Open-Closed Principle, as extending the system with new product types could necessitate modifying this central service’s core logic. It also still requires complex data synchronization (as discussed next) for the Order Service to maintain an accurate state based on actions performed by the specialized services.
This decomposition, while simpler on the surface by removing a service, may still not align cleanly with end-to-end customer journeys or distinct business capabilities, often driven by the attempt to centralize state and rules within the Order Service. Defining better boundaries remains notoriously difficult, requiring deep domain knowledge; collaborative techniques like Event Storming, as described by Alberto Brandolini, can be invaluable for discovering more natural, capability-aligned service cuts. However, fragmentation resulting from these difficult early boundary decisions often makes the overall process harder to manage and directly leads to subsequent pitfalls involving data synchronization and integration complexity.
Symptom: Troublesome frontend integration
One of the most immediate and often painful symptoms arising from these architectural boundaries is a complex and burdensome frontend integration process. Even in this simplified architecture, where the Order Service tracks the high-level item state, the frontend application is still forced to act as a complex data integrator because the complete picture isn’t available from a single source.
In our Fragmented Bookstore example, this pain remains clear when building the user-facing “Order Status” page. To display complete, meaningful information for each item:
- The frontend must query the Order Service to retrieve the high-level status (e.g., SHIPPED or ACCESS_GRANTED) that it maintains.
- However, it still needs to make additional, separate API calls to fetch the essential contextual details:
- To the HardcoverLogistics Service for the shipping carrier and tracking number if it’s a shipped hardcover.
- To the EbookProvisioning Service for the download link or library access instructions if it’s a provisioned ebook.
This means the frontend must query 3 different services (Order, HardcoverLogistics, EbookProvisioning) and implement significant client-side logic to aggregate this data, effectively unifying a state model that remains fragmented across the backend. This inherently leads to a more complex, potentially slower, and harder-to-maintain frontend codebase, contradicting the goal of keeping frontends focused on presentation (“dumb”) while the backend serves up ready-to-use information.
Furthermore, as the diagram suggests the frontend might send mutations directly to specialized services while reading state from the Order Service, a significant eventual consistency issue arises. A user could successfully perform a mutation to EbookProvisioning, but when the frontend refreshes its data by querying the Order Service, the state reflecting that action might not have been updated there yet (due to propagation delays). This lag creates confusing inconsistencies for the user.
The application’s resilience also suffers, as the failure of any of these three services could impede the frontend’s ability to display complete information. This problematic inconsistency and frontend complexity directly motivates exploring solutions, starting with the need to effectively sync state changes that happen in the specialized services (HardcoverLogistics, EbookProvisioning) back to the Order Service to provide a more unified and timely view.
Forced state synchronization & bi-directional data flow
A direct consequence of splitting tightly coupled data and processes is the need for state synchronization, which inherently creates bi-directional data flows and associated complexities. In the Fragmented Bookstore architecture, as depicted now with synchronization:
- The Order Service holds the authoritative high-level status but relies on HardcoverLogistics and EbookProvisioning to perform the actions that change the actual fulfillment state.
- To keep the Order Service state accurate, the specialized services must report their outcomes back.
- This establishes a bi-directional flow: process events flow out from Order Service (ProcessHardcoverCommand, ProcessEbookCommand), while status update events flow back into it.
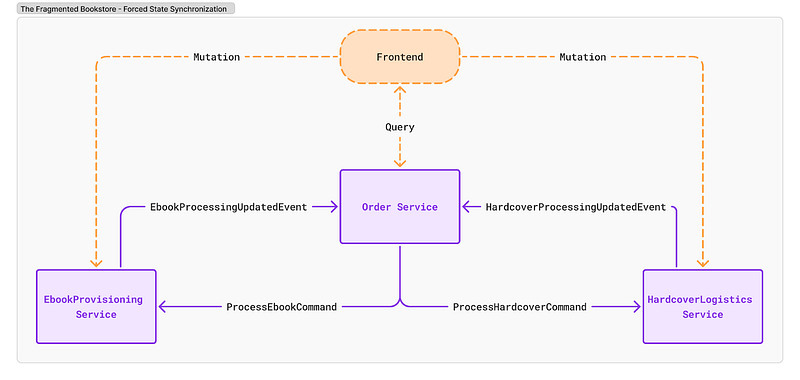
How the frontend becomes simpler: The primary benefit of this architecture is simplifying the frontend integration. Because the Order Service now consumes these update events, the frontend can ideally query only the Order Service to retrieve a complete and up-to-date view of each item’s status and details from a single source of truth. This eliminates the need for complex frontend logic that was previously required to make multiple API calls, aggregate data from different sources (Order, HardcoverLogistics, EbookProvisioning), map different data structures, and handle errors across those multiple interactions. The frontend can revert to a simpler role, primarily focused on presenting the consolidated information served by the Order Service.
Why eventual consistency remains a concern: Due to the asynchronous nature of the event-driven updates, there remains an inherent time delay (the inconsistency window) between an action completing in the specialized services and the Order Service actually receiving and processing that event to update its own state. During this window, the state within Order Service still lags slightly behind the absolute latest reality known only to the specialized services at that instant. This means queries to Order Service might occasionally return stale data.
Furthermore, the backend complexity persists or shifts: the Order Service now requires robust synchronization logic (handling idempotency, correlation, potential errors) to reliably process these incoming events, and the system still has the overhead related to event traffic and monitoring. Complexity might also increase due to having to build state stores on the relevant sync events. Thus, while state synchronization greatly improves the frontend experience compared to the previous fragmented querying, the underlying system operates on an eventually consistent model whose implications must still be carefully managed.
Splitting tightly coupled data and processes
This pitfall occurs when logically interdependent data and the processes that operate intimately on that data are placed into separate services. Our Fragmented Bookstore architecture illustrates this by separating the item’s high-level status and common restrictions from the detailed information, type-specific sub-states, and actions associated with order fulfillment:
- The Order Service holds the high-level status (e.g., SHIPPED, ACCESS_GRANTED) and common data/restrictions.
- The HardcoverLogistics Service, however, performs the actual shipping action, holds the crucial details giving context to that status (like tracking number), and manages its own internal sub-states related to the physical process.
- Similarly, the EbookProvisioning Service performs the access granting action, holds the relevant details (like access links or keys), and manages internal sub-states specific to digital processing.
While aiming for separation of concerns, this ignores the tight coupling between an item’s status and its meaningful context, fragmenting the complete view of an item’s state. Consequently, consumers like the frontend must query multiple services to assemble a full picture, and complex synchronization is needed just to keep the Order Service state reasonably aligned with reality, creating significant integration hurdles.
As an architect you should be brave enough to revisit those service boundaries that seemed like pure genius six months ago, because systems (and our understanding) inevitably evolve.
Addressing the fragmentation caused by splitting tightly coupled concerns requires critically re-evaluating the existing service boundaries. A crucial first step involves analyzing the current services based on their responsibilities, the core data entities they contain, the events they emit, and the specific business processes they handle. Grabbing your teammates for a brainstorming session is often the best way forward — collaborative discussions frequently uncover simpler approaches. This analysis often leads towards solutions that group entities and processes more cohesively, ensuring data lives closer to the logic that operates on it.
In our bookstore example, this might lead to considering combining the specialized HardcoverLogistics and EbookProvisioning services into a single, unified Delivery Service. The aim could be an architecture where queries for status primarily target the Order Service (which receives synced updates), while mutations related to fulfillment target this new Delivery Service.
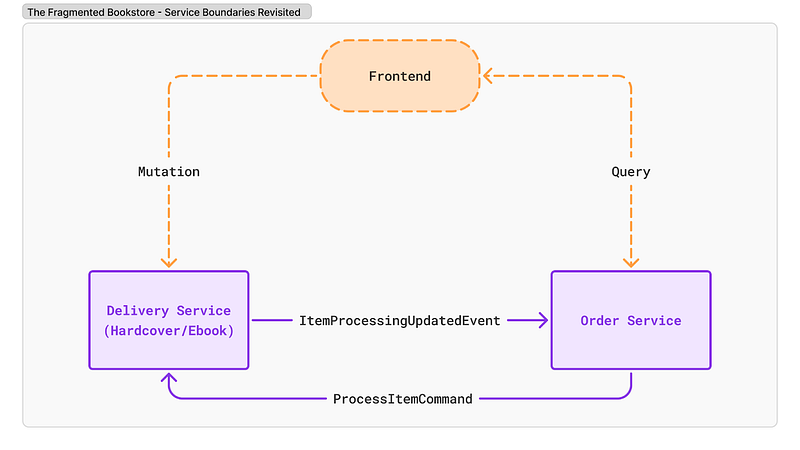
How the frontend becomes simpler: Queries for delivery status and details (like tracking numbers or access links) for both item types could target this single Delivery Service. This significantly reduces the need for the frontend to aggregate data from multiple sources and manage logic specific to each specialized service.
Why eventual consistency is mitigated, but not eliminated: Eventual consistency would still exist between the Order Service and this combined Delivery Service due to asynchronous event-based updates flowing between them (like ItemShippedEvent or LicenseProvidedEvent). However, the user-facing manifestation might be reduced, as the frontend interacts with fewer distinct backend services for fulfillment data, decreasing the chance of displaying contradictory states fetched simultaneously from different sources, although the backend still needs to manage the inherent update delays.
Of course, the “simplest” way to solve cross-service sync issues — and therefore eliminate lags due to eventual consistency — would be to just put everything (Order, HardcoverLogistics, EbookProvisioning) back into one big service again. Problem solved, right? Well, except then we’d have reinvented the monolith and waved goodbye to the agility and resilience microservices were supposed to bring. Also, this might not even be possible because the services are owned by different teams, or some data underlie specific regulations. Finding the right balance for service boundaries, avoiding both fragmentation and monolithic blobs, remains the core task.
Symptom: Potential for code duplication across “similar” services
Despite distinct core functions, services handling similar roles in the overall process, like the separate HardcoverLogistics Service and EbookProvisioning Service in our initial bookstore design, can inadvertently lead to duplicated effort in surrounding functionalities. Redundancy often appears in implementing common patterns such as reporting status updates back to the central Order Service, handling communication errors, integrating cross-cutting concerns like logging or notifications, or managing event bus interaction boilerplate. This violates the DRY principle, increasing maintenance overhead as fixes or updates must be applied in multiple codebases, and risking inconsistencies over time.
A strategy here involves deliberately re-assessing these related services. By analyzing the actual overlap in logic versus the truly distinct parts, we can weigh the ongoing cost of maintaining duplication against the challenges of merging responsibilities. For example, combining HardcoverLogistics and EbookProvisioning into a single service (similarly to the aforementioned Delivery Service could potentially reduce code duplication for those shared patterns. However, this approach comes with significant caveats, primarily the risk of introducing substantial internal complexity by forcing the single service to manage workflows and handle numerous entity-specific edge cases through conditional logic. A good strategy here is to evaluate potential processes that could be safely extracted to a different service without adding complexity or triggering new data syncs. The decision requires carefully evaluating whether the benefit of reduced duplication outweighs the potential complexity and coupling introduced within a larger, combined service.
Lessons learned: Defining and redefining service boundaries
Designing effective microservice boundaries is undoubtedly challenging, often feeling like navigating the maze described earlier. Our exploration of the Fragmented Bookstore illustrated how initial logical cuts might seem right, but experience often reveals deeper complexities. Here are key lessons gleaned from tackling such architectural challenges:
- Slice strategically: Common strategies for initially defining service boundaries include aligning with distinct business domains or capabilities (using Domain-Driven Design), mapping to key customer journeys, considering team ownership structures, or ensuring clear data ownership per service. While these provide excellent starting points, the bookstore example highlighted that deeper analysis, perhaps using collaborative techniques like Event Storming, is crucial. This validation helps uncover the true seams in the domain and avoid fragmentation based on initial assumptions or superficial differences, ensuring boundaries are genuinely cohesive before diving too deep into implementation.
- Listen to the symptoms: Troublesome frontend integration requiring complex data aggregation across services is a major red flag signaling potential boundary issues. Similarly, the forced introduction of complex state synchronization mechanisms often indicates that tightly coupled data and behavior might have been incorrectly separated earlier in the design. Treat these not just as technical hurdles, but as potential symptoms of deeper boundary issues needing attention. Ask yourself: Are two services always deployed together? If so, the boundaries should probably be reconsidered.
- Prioritize cohesion: A core issue highlighted was the separation of state management from the actions and detailed context handled by specialized services. A key lesson is to strive for high cohesion within your services by keeping data/state as close as possible to the business logic that operates on it, minimizing the need for complex cross-service synchronization and making each service’s state more intrinsically meaningful.
- Embrace iteration: Initial boundary decisions are hypotheses based on current understanding. Be prepared to critically re-evaluate and refactor boundaries based on operational feedback, evolving domain knowledge, or the emergence of the symptoms mentioned above. Collaboration and iterative refinement are essential parts of evolving a microservice architecture effectively, not signs of failed initial design.
- Design for your consumers: Service boundaries define APIs. Think about who needs what data, especially frontends. Designing boundaries and APIs that provide cohesive data views relevant to consumer use cases helps avoid pushing complex aggregation logic onto them and reduces their coupling to the internal structure of the backend.
Final thoughts
Think of each microservice as a small startup. Does it provide enough value on its own to justify being its own service? If not, it may need to be consolidated. Slicing microservices requires balancing technical, business, and organizational considerations. The goal is to create independent, purposeful services that evolve smoothly as your system grows.
It’s time to build
Microservices promise much but navigating their complexity is key to realizing those benefits. At &, we’ve learned that success isn’t automatic; it requires proactively avoiding the common ‘wrong turns’ in the architectural maze — such as unclear boundaries, tangled data, or complex integrations. Ultimately, thriving with microservices requires translating experience into specific design actions: ensuring service boundaries simplify workflows rather than complicate them, preventing tight coupling that hinders independent changes, managing data consistency deliberately across services, planning for cross-cutting needs like reporting early, and designing APIs that ease frontend integration instead of burdening it. Crucially, this also means being unafraid to critically revisit these initial design choices, developing architectural plans that evolve and adapt as domain understanding deepens or new information emerges during development. By recognizing these potential challenges and embracing both careful initial design and iterative refinement tailored to your unique context, you can truly harness the power of microservices.
Let me know what you think and leave a comment or shoot me an email at matthias.eder@andamp.io.

Explore Our Latest Insights
Stay updated with our expert articles and tips.






Discuss Your Web Development Project with Our Experts Today.
Discover how our tailored web development solutions can elevate your business to new heights.
Stay Connected with Us
Follow us on social media for the latest insights and updates in the tech industry.