
You can read a lot about observability on various platforms, as it has become increasingly important to assess a system’s current state by analyzing the data it produces. However, the topic can initially seem very complex, and it’s easy to feel overwhelmed by the names of products, technologies, and concepts. In my previous blog post, we looked into some key foundations of observability, including the three pillars, the responsibilities of the platform and delivery team, and the OpenTelemetry framework.
In this post, we will build on the knowledge from our previous post and put it into practice. The goal of this blog post is to bridge these knowledge gaps and demonstrate a minimal setup of an observability solution, helping to establish a better understanding of the subject.
Understanding the Observability Solution: OpenTelemetry and the LGTM Stack
Before we dive into the orchestration code and start deploying observability tools, it’s crucial to clearly understand where each component of our observability solution will be placed and why. The setup is divided into three parts: Application Landscape, OpenTelemetry Collector, and LGTM (Loki, Grafana, Tempo, Mimir) Stack
Modeling a Real-World Scenario: A Simple Application Landscape
The application landscape represents a typical service architecture commonly found in many organizations. Depending on the organization, this mesh of intercommunicating services can range from a few services to several hundred. For simplicity, our scenario features a limited number of services to maintain a clear overview of the overall structure.
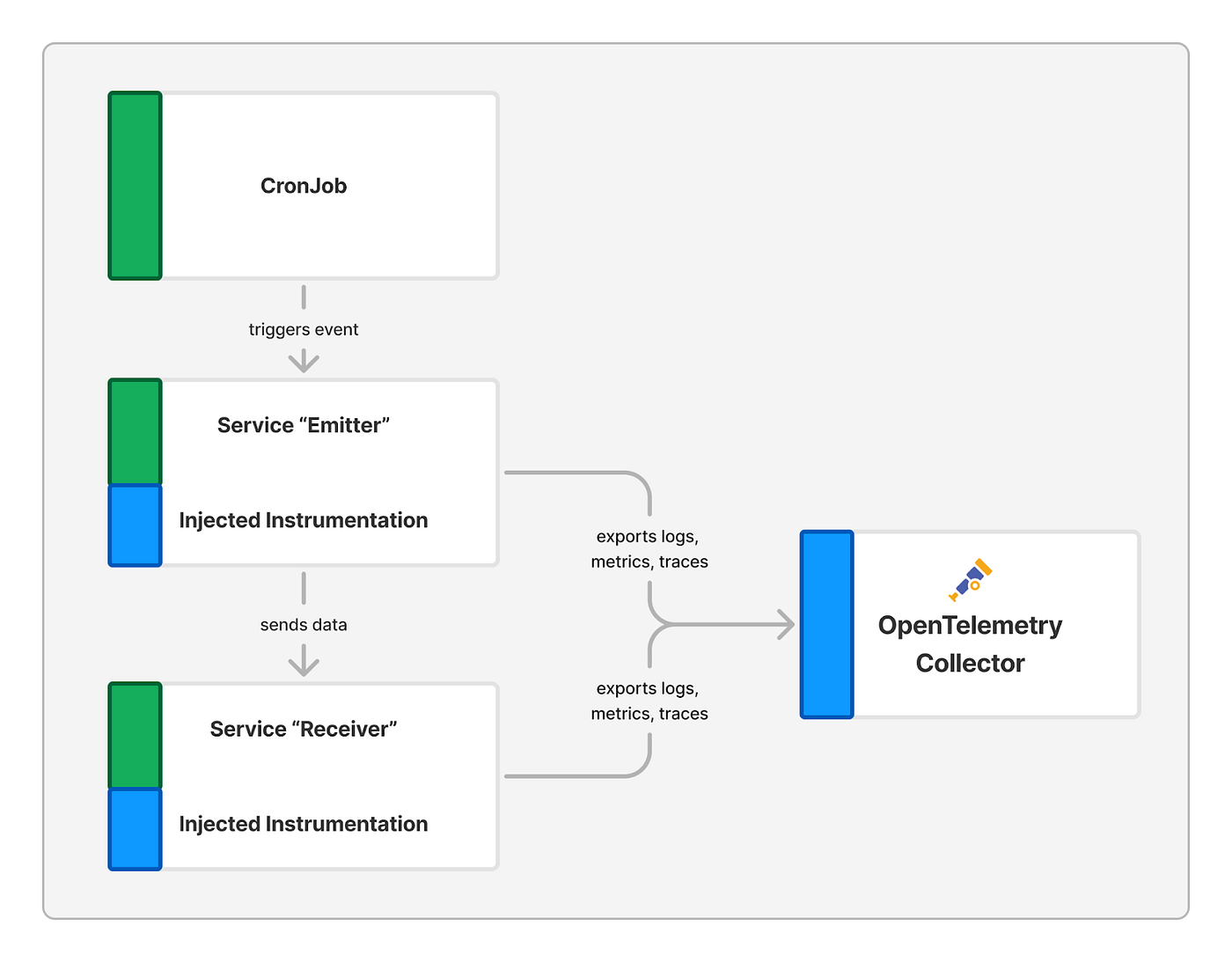
In our case, we have a cron job that triggers an event in the service called “Emitter” every few minutes. Upon being triggered, the “Emitter” starts sending data to the “Receiver” service.
This setup ensures a continuous stream of data production, eliminating the need to manually trigger events to test the effectiveness of our observability solution. The cron job automates this process, allowing us to focus on configuring and verifying our observability tools.

Sending Telemetry Data to the OpenTelemetry Collector
In the application landscape, our services are operational, but their telemetry data are not yet ingested. We need to establish a procedure to collect metrics, logs, and traces from each service and integrate them into our observability solution. For this, we use instrumentation. In the OpenTelemetry ecosystem, there are two approaches to instrumenting our services:
- Zero-code Instrumentation: Zero-code solutions are ideal for initial setups or when application modification isn’t feasible. They provide robust telemetry data for the external libraries integrated into your application and its runtime environment, offering valuable insights into peripheral activities.
- Code-based Instrumentation: This approach allows for deeper insights and rich telemetry data directly from your application. By using the OpenTelemetry API, you can generate detailed telemetry data from within your application, complementing the telemetry data generated by zero-code solutions.
For our implementation, we opt for the Zero-code solution for simplicity. By using this approach, a JAR agent, which is a Java archive file that automatically instruments and captures telemetry data, is attached to our services to capture telemetry data from various popular libraries and frameworks. In addition to the JAR agent, we also need a sidecar on our deployment, which will transmit the telemetry data from our services to a central point, the OpenTelemetry Collector.
The OpenTelemetry Collector provides a vendor-neutral framework for receiving, processing, and exporting telemetry data. It supports receiving data in various formats (such as OTLP, Jaeger, Prometheus, among many commercial/proprietary tools) and transmitting it to one or multiple .
For our use case, the OpenTelemetry Collector will receive telemetry data from the sidecars running alongside our services and then push this data to the appropriate tools in our LGTM stack for further processing, visualization and storage.
A Brief Overview of the LGTM Stack: Loki, Grafana, Tempo, and Mimir
Now that we have managed to get our telemetry data to a centralized point, that distributes them to the correct backend components, we should take a deeper look at the LGTM stack, which stands for Loki-for logs, Grafana — for dashboards and visualization, Tempo — for traces, and Mimir — for metrics. To give you a short recap of what each component in this stack does, we will summarize the key ideas behind them. For more detailed information, please refer to the documentation https://grafana.com/docs/.

Loki
Grafana Loki is an open-source project that forms a comprehensive logging stack. It simplifies operations and significantly lowers costs through a small index and highly compressed chunks. Unlike other logging systems, Loki indexes only metadata (labels) rather than the log contents, making it highly cost-effective and scalable.
Mimir
Grafana Mimir is an open-source project offering horizontally scalable, highly available, multi-tenant, long-term storage for Prometheus and OpenTelemetry metrics. It allows users to ingest metrics, run queries, create new data with recording rules, and set up alerting rules across multiple tenants, leveraging tenant federation.
Tempo
Grafana Tempo is an open-source, high-scale distributed tracing backend that is easy to use. It enables you to search for traces, generate metrics from spans, and link tracing data with logs and metrics. Tempo is cost-efficient, requiring only object storage to operate.
Grafana
Grafana is an open-source project that enables you to query, visualize, alert on, and explore your metrics, logs, and traces from various sources. Data source plugins support querying from time-series databases like Prometheus and CloudWatch, logging tools like Loki and Elasticsearch, tracing backend like Tempo, NoSQL/SQL databases such as Postgres, and many more.
From a high-level perspective, the structure and division between these components are straightforward and intuitive. OpenTelemetry routes the data streams to the appropriate backend component based on the signal type of telemetry data. Each component stores the data efficiently, ensuring high availability and optimization. However, simply having data stored in databases isn’t sufficient for effectively analyzing issues or bottlenecks in our application landscape. This is where Grafana comes into play. Grafana serves as the unified UI for the entire stack, allowing for the querying, visualization, alerting, and exploration of metrics, logs, and traces from various data sources through live dashboards with insightful visualizations.
Hands-on Guide: Setting Up the Observability Solution
What to Expect from This Tutorial
A short disclaimer before we start the hands-on section: We will not go into detail about every line of orchestration code. We assume that basic knowledge about Kubernetes is present. Therefore, the focus is more on better illustrating the integration and interrelation of the components. However, references or links to the repository are frequently provided, where additional information can be obtained. We also do not recommend using this exact configuration in a production environment, as there is no failover concept, backup plan, or security measures implemented or considered. These aspects were left out due to complexity reasons.
For deploying our services and components, we use Argo CD to encapsulate them properly. Throughout the rest of the text, you will find references to Argo CD in deployments and configuration. However, Argo CD is not required to achieve this setup. If you prefer to set this up without Argo CD, you will need to make some adjustments, especially when deploying Helm charts.
Operator & Controller
In this hands-on guide, we’ll leverage Kubernetes operator and controller to provide the necessary functionality to get this setup working. The controller and operator that need to be installed are as follows:
Those were the newest versions when the blog post was created. When you try to recreate this setup, you may consider choosing a newer version. However, this might lead to incompatibilities or break functionality related to the configuration of the components.
Deploying the Application Landscape and OpenTelemetry Collector
It’s finally time to dive into some orchestration code. To build our observability solution, we begin with the workloads that generate telemetry data. By starting here, we can later integrate all the necessary components for exposing and visualizing this data in a step-by-step manner.
Our application landscape is relatively simple. We have two deployments, each running a pod with a service containing a Spring Boot application. These applications have REST endpoints with implemented business logic, generating logs, traces, and metrics. Additionally, they have REST clients configured, enabling us to connect the two services. Consequently, when one application receives a REST call, it produces logs, metrics, and traces, and then makes a REST call to the other pod, which, in turn, generates its own set of telemetry data.
To avoid the need to manually trigger these REST endpoints, a cron job is set up to run every 5 minutes. For more details on the deployments, please refer to this commit, which contains the orchestration for the entire application landscape.
Now we come to the point where we want to ship our telemetry data to a centralized location: the OpenTelemetry Collector. To achieve this, we first need to deploy two components: the OpenTelemetry Collector and the Instrumentation.
The OpenTelemetry Collector is responsible for receiving, processing, and exporting our data to the respective monitoring stack components. The Instrumentation, on the other hand, defines the injected sidecar that will be added to our applications in the application landscape.
Configuring the OpenTelemetry Collector
We will start with a simple configuration for the OpenTelemetry Collector. We need to define “receivers,” “exporters,” and “service” to get the application running. For the receiver, we specify that the OpenTelemetry Collector provides an endpoint on port 4318 to receive telemetry data. In the service section, we simply connect the log pipeline from the receiver to the exporter. Currently, our exporter is set to “debug,” which writes the logs to the console. Later on, we will properly configure this exporter to ship our logs to Loki. For now, writing the logs to the console on the OpenTelemetry Collector is sufficient to confirm that the logs are exporting correctly from the application landscape to the OpenTelemetry Collector. Generally, this debug approach can also be used for traces and metrics, and it is very helpful during the initial setup.
The OpenTelemetry Collector configuration is very flexible and offers functionalities such as filtering, batching, and redacting sensitive information. For more information, read here. To better understand how the pipelines work together, we recommend reading this.
Configuring Automatic Instrumentation
To manage automatic instrumentation, the Operator needs to be configured to identify which pods to instrument and which automatic instrumentation to use for those pods. The instrumentation acts as a blueprint, enabling the proper configuration of sidecars. In our case, we configured it like this:
- The exporter defines where the telemetry data is sent. Therefore, we specify the path for the OpenTelemetry Collector in the configuration.
- The propagators configure inter-process context propagation.
- The sampler defines the sampling configuration. In our case, we want 100% of our traces to be exported to the OpenTelemetry Collector. Note that this configuration is only suitable for test environments, as it would produce a substantial amount of data in production.
- In the java section, we define the image to be used for the sidecar. Since our service includes the Micrometer library, we also use the built-in configuration for Micrometer to obtain additional metrics.
Enabling Automatic Instrumentation
The last step is to apply the Kubernetes annotations to our deployment. For the automatic instrumentation and auto-injection of the sidecar to work, you may need to restart the deployments. This should be done after deploying the instrumentation, the OpenTelemetry Collector, and applying the Kubernetes annotations.
Validating the Configuration
Once you see the sidecar being deployed, you just need to wait until the cron job generates some logs. The logs that appear in the containers of the application landscape should now also be accessible in the OpenTelemetry Collector.
If that is not the case, then you should check the logs in the application landscape container. The sidecars will produce helpful logs that can indicate issues, such as a non-working or incorrectly configured connection to the OpenTelemetry Collector.
This entire section is also covered in this commit.
Setting Up Logs with Loki
Deploying Loki
We have successfully configured our logs to be exported to the OpenTelemetry Collector. Now, we need to determine how to export the logs to Loki. To achieve this, we will start by deploying Loki through a Helm chart in our namespace using the Argo CD application. If you are not familiar with the Argo CD application, we recommend reading the documentation.
For the configuration of the Helm chart, we aim to keep the Loki instance as simple as possible. Since this is only for demonstration purposes, we minimize the number of replicas. We also set the deployment mode to SingleBinary, which does not provide high availability and should be used when you have only a few tens of GB/day. Additionally, we use the storage type “filesystem” to avoid dependencies on specific vendors or storage restrictions. This approach, of course, is not ideal for a production environment.
Configuring OpenTelemetry Collector for Loki
After deploying Loki, we can return to the OpenTelemetry Collector and configure the exporter correctly so that the logs are now exported to Loki.
We need to configure the exporter with the correct Loki endpoint and ensure that the receiver and exporter are properly connected in the pipelines. Once that’s done, we can apply the updated OpenTelemetry configuration.
Since OpenTelemetry and Loki’s logs are relatively sparse about the export of logs, we need to manually check if our wiring was correct, as there is no other good way to verify the functionality. To do this, we check the Write-Ahead Log (WAL) on Loki. On the Loki pod, we execute the following command:
If we receive some result containing our logging statement, for example “Received data: Traffic package 3”, then the wiring was successful.
Deploying and Configuring Grafana for Loki
The logs are now being stored in Loki, but we need a method to access them visually and query for certain keywords. To achieve this, we will deploy Grafana. Since we have the Grafana Operator installed, we can deploy a Grafana CRD, which will reduce overhead and simplify the deployment.
To configure Grafana, we define the credentials needed for accessing the Grafana UI.
To complete the logging setup, we need to connect Grafana to Loki using a Grafana data source. For that, we deploy the following data source:
The configuration of the data source is straightforward. We simply insert the endpoint of our Loki instance along with some other basic required information. After applying the changes, we should see a new data source in Grafana.
With this data source, we can filter the logs based on our service name. For example, like this:

Great! We have successfully exported our logs from our application landscape to the OpenTelemetry Collector, which in turn exported the logs to Loki. Grafana then uses Loki as a data source to visualize the logs. The same principle of wiring and connecting will be used for traces and metrics.
Since it is sometimes easier to follow the wiring of components directly in a codebase, we have covered this section in this commit.
Setting Up Metrics with Mimir
Deploying Mimir
Similar to our approach with Loki, we will apply the same method for metrics. Before configuring our OpenTelemetry Collector, we will start by deploying Mimir.
Here as well, we use a Helm chart to deploy the component. In this case, we use the Helm chart from SkyCloud instead of Grafana directly, as they offer different deployment modes. We choose the “monolithic” deployment mode. This deployment mode, along with the other configuration settings, allows for a very minimal deployment of Mimir, which is sufficient for our needs.
Configuring OpenTelemetry Collector for Mimir
Once Mimir is deployed, we can start by adding the necessary configuration to our OpenTelemetry Collector to export the metrics received from our application landscape to Mimir.
Following our procedure for configuring logs, we will add a receiver and an exporter to the OpenTelemetry configuration. In this case, we add the endpoint “http://mimir-nginx:80/api/v1/push" for the exporter.
To verify that the metrics are being shipped to Mimir, we can check the logs on the mimir-nginx. If the logs contain such logging statements, then we know that the wiring of the OpenTelemetry Collector was correct.
Configuring Grafana for Mimir
Since we have already deployed Grafana in the Loki section, we do not need to do that again here. However, we do need to deploy the data source that connects Grafana to Mimir. Specifically, we will deploy the following configuration:
Here again, we need to set the correct URL for Mimir’s endpoint. Mimir is highly compatible with Prometheus, ingesting and storing its metrics, and understanding PromQL. Therefore, Mimir is defined as a Prometheus data source in our configuration.
After deploying this data source, we can refresh Grafana and check if the metrics are available. To verify the functionality, we imported a public dashboard for Spring Boot and configured it to use Mimir as the data source. Here is an example:
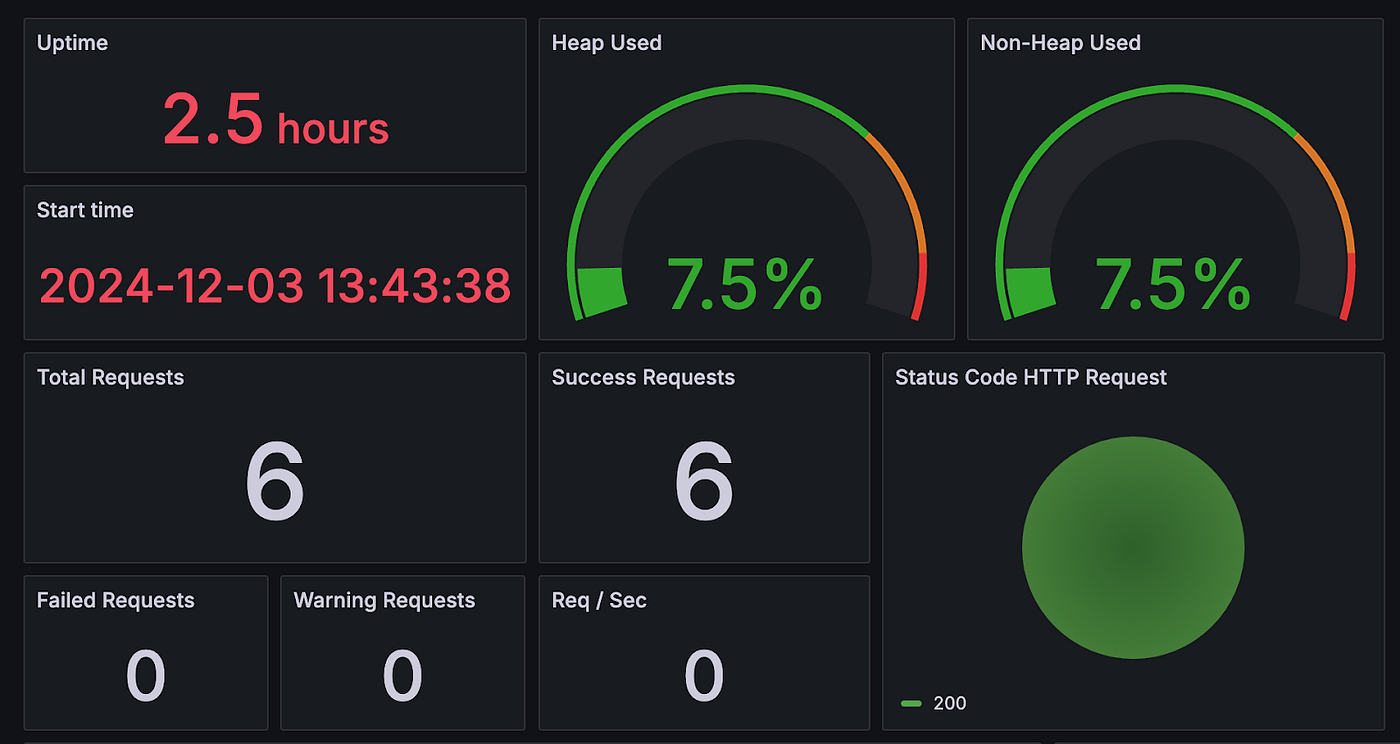
This is only a subset of all the available metrics. There are also metrics related to the JVM, logs, and database activity. The zero-code auto instrumentation does a great job of providing us with a solid base of necessary metrics to start with.
We have also provided a concise commit so you can see the entire configuration at a code level.
Setting Up Traces with Tempo
Deploying Tempo
Now we come to the last telemetry data in our observability solution: traces. For traces, we will use Tempo. Let’s start by deploying Tempo through a Helm chart in our namespace.
The Helm chart already provides a minimal single binary mode, so we do not need to add any additional configuration.
Configuring OpenTelemetry Collector for Tempo
For the final adjustment, we need to update the OpenTelemetry configuration by adding the exporter and pipeline for Tempo. With this addition, we will finalize the OpenTelemetry configuration.
We can also use the Write-Ahead Log (WAL) of Tempo to verify if the traces are being exported to Tempo. To do this, we use the following command:
Configuring Grafana for Tempo
We follow the same process as we did for Mimir and Loki by deploying a Grafana data source for Tempo, using the correct Tempo endpoint provided by the Helm chart deployment.
We can now select the Tempo data source in Grafana to display traces between our services. In the provided example, you can easily see the importance of traces. We can follow the communication paths between the services and also observe how long a service takes to process an incoming request. This makes identifying bottlenecks much easier in a large microservice architecture.

With the setup of Tempo, we conclude our practical guide for deploying an observability solution. As with the other sections, we have also provided a commit here that covers the most important parts of deploying and configuring our observability components.
Key Takeaways and Future Directions
In this blog post, we demonstrated how to easily set up and run an observability solution using open-source components. Initially, this topic can seem complex. Getting the connections and configurations of OpenTelemetry to work required some trial and error. Additionally, the documentation is often unclear or sometimes even missing. We frequently found ourselves checking open issues or merge requests on GitHub, and browsing Stack Overflow to see how things need to be configured or deployed. However, when broken down into several parts, as we did in this blog post, the topic becomes manageable and intuitive.
The observability solution presented here covers some foundational aspects of observability. However, there are several options to extend this setup. For one, we would really like to implement Pyroscope for profiling. This would provide an even deeper and more extensive view of the application. Another tool we are eager to try is Grafana Alloy, which was introduced at GrafanaCon 2024. Grafana’s OpenTelemetry Collector appears to be highly flexible and simplifies problem-solving with an embedded debugging UI accessible via the Alloy HTTP server. Lastly, we would like to see an alert manager added to the solution. Seeing alerts being handled and delivered to the respective team would make our proposed observability solution more production-ready.
It’s Time to Observe Your Infrastructure
As businesses continue to evolve in the cloud era, having the right observability tools is crucial for maintaining system performance and reliability. At &, we specialize in providing comprehensive monitoring solutions using stacks like LGTM to give you deep insights into your cloud native infrastructure. Our expertise in cloud native environments ensures that we can help you enhance your observability practices to find the perfect fit for your needs.
Contact us today to learn more about how we can help you stay ahead with tailored observability solutions, advanced monitoring strategies, and dedicated workshops on these topics.

Explore Our Latest Insights
Stay updated with our expert articles and tips.

Discuss Your Web Development Project with Our Experts Today.
Discover how our tailored web development solutions can elevate your business to new heights.
Stay Connected with Us
Follow us on social media for the latest insights and updates in the tech industry.