
Anyone who has managed Kubernetes workloads knows the routine. A pod is crashing, a service is unreachable, or a deployment is stuck. The investigation begins: a series of kubectl get, describe, and logs commands, trying to piece together clues from YAML files, event logs, and resource states. What if, instead of this manual scavenger hunt, you could simply ask the cluster what’s wrong in plain English?
This is the promise of AI assistants for Kubernetes. These are not just chatbots; they are capable assistants that can reason about problems, use their capabilities to investigate issues, and even perform proactive tasks like detecting anomalies or auditing security configurations. By connecting an AI model to your cluster’s API, you can delegate the tedious parts of operations and get straight to solving problems.
In this post, we’ll go from theory to practice. We’ll start by explaining the core concepts behind the Model-Context Protocol (MCP), the standard that makes these capable AI assistants possible. Then, we’ll walk through a step-by-step setup of kAgent, an open-source AI assistant, and configure it to work with a Kubernetes cluster. We’ll put our new agent to the test by using it to solve three common challenges, and finally, we’ll analyze the results and discuss important considerations for using these systems in real-world scenarios.
Understanding the Foundations: Agents, Tools, and MCP
To understand how these AI assistants work, it’s helpful to define a few core concepts. At the center is the Agent, a specialized program that uses an AI model for reasoning and decision-making. On its own, an agent is like a brain without hands; it can think, but it can’t interact with the outside world.
This is where Tools come in. A Tool is a function that contains the actual code to perform an action, like running a command or querying an API. When an agent decides it needs to do something, it calls the appropriate Tool, which acts as its “hands” to execute the task and return the results.
Connecting agents to tools has traditionally required significant custom engineering. The MCP, originally developed by Anthropic, was created to solve this by providing a standardized, open protocol for these interactions. This simplifies how AI agents connect to external systems, reducing the engineering effort and financial cost of building and maintaining these integrations.
The MCP architecture consists of four key components:
- Host (AI Application): The user-facing part of the system, such as a chat interface or an IDE extension. It orchestrates the interaction by taking the user’s query, passing it to the AI model, and presenting the final result.
- MCP Client: A component that runs within the Host application. It handles the low-level details of communication, such as establishing a connection with an MCP Server, discovering its available tools, and managing the flow of requests and responses.
- MCP Server: A program that acts as a bridge between the AI agent (via the MCP Client) and a data source. It contains the actual code for the “Tools” and makes them available to the agent through the standardized MCP protocol. For example, a server could expose tools for interacting with the Kubernetes API.
- Data Sources and Services: The actual systems or services that the agent needs to interact with. This could be anything from a local file system or a database to a remote cloud service or the Kubernetes API itself.

The interaction is straightforward: A user submits a query to the Host application. The AI model processes it and determines if it needs to use a tool. If so, the Host directs its MCP Client to send a request to the corresponding MCP Server. The Server executes the request against the data source and returns the result, which the AI then uses to formulate a final response.
Introducing kAgent: A Kubernetes AI Assistant
To see these concepts in a practical application, we will use kAgent, an open-source framework for bringing AI to Kubernetes. It is designed to help engineers troubleshoot issues and automate operational tasks by allowing them to interact with a cluster using natural language. kAgent provides an extensible foundation for adding custom tools, which makes it a practical example for demonstrating the Model-Context Protocol in action. It also includes a dashboard and a command-line interface (CLI) for interacting with the configured agents.
When installed in a Kubernetes cluster, kAgent runs as a standard deployment. This deployment is a self-contained implementation of the MCP architecture, functioning as the Host application, including the MCP Client, and running a built-in MCP Server. The primary purpose of this architecture is to expose kAgent’s native Kubernetes functions as Tools that an AI agent can use. For example, the k8s_get_resources tool is a function that, when triggered by the agent, runs the equivalent of a kubectl get command on the cluster, allowing the agent to analyze the output.
Setting Up Your kAgent Environment
The following steps will guide you through setting up the kAgent operator and configuring an agent.
Optional: Set Up a Local Kubernetes Environment
If you don’t have an existing Kubernetes cluster, you can set one up locally for testing purposes. A popular tool for this is Minikube, which creates a single-node cluster on your machine. You can follow the official Minikube documentation to get it installed and running.
1. Deploy kAgent
The first required step is to install the kAgent operator in your Kubernetes cluster. The operator manages the lifecycle of kAgent’s custom resources. Detailed instructions for this process are available in the official documentation.
2. Define a Provider
Next, you need to specify which AI provider kAgent should use. It supports several options, including Anthropic, Google Vertex AI, Ollama, and OpenAI, as well as custom models. For this guide, we will use Google Vertex AI. The configuration involves setting up the necessary credentials and connection details as outlined in the provider-specific documentation.
3. Configure the Agent
With the operator running and the provider defined, the final step is to configure the agent by creating a set of Kubernetes resources.
First, we create a Secret to securely store the credentials for our chosen AI provider. In this case, it holds the Application Default Credentials for Google Cloud.
Next, we define a ModelConfig Custom Resource. This resource defines a specific AI model configuration and connects it to the secret we just created. In this case, we configure it to use the Gemini 1.5 Pro model on Vertex AI, providing the necessary project ID and location.
Finally, we create the Agent Custom Resource. This resource ties everything together. We reference the ModelConfig, provide a systemMessage to guide the AI’s behavior, and define the specific tools the agent is allowed to use. For the systemMessage, we will use the default text provided by kAgent. To maintain a conservative security posture, we will only grant the agent access to read-only tools for getting information about Kubernetes resources. This means the agent can observe the state of the cluster but is explicitly prevented from making any changes to its resources.
4. Verify the Setup
Once all the resources are applied, the final step is to verify that the agent is running correctly. You can do this by accessing the kAgent UI through the corresponding Kubernetes service. If you are using Minikube, you can expose the service and get the URL with the following command:
Opening this URL in your browser should display the kAgent dashboard. You should see the model and agent you configured listed in the UI.

If they don’t appear after a short while, a common first step is to restart the kAgent deployment. If the issue persists, checking the logs of the kagent deployment is the best way to diagnose the problem. Errors such as API rate limiting from the provider are often only visible in the logs.
Putting kAgent to the Test: Real-World Scenarios
With our agent configured and running, we can now evaluate its ability to diagnose common Kubernetes issues. We will present it with three scenarios that a DevOps engineer might encounter.
Scenario 1: Diagnosing a Service Port Mismatch
For the first test, we create a common service wiring issue. A NodePort service is configured to accept traffic on port 80 and it incorrectly forwards that traffic to targetPort 81. The container in the Pod it selects, however, is listening on port 80, creating a mismatch that prevents connectivity. We then prompt the agent to diagnose the problem:
“I’m experiencing a connectivity issue with the testcase1-deployment-8d97797b6-r644d deployment in the testcase1 namespace. I’m trying to connect via its NodePort on port 80, but it’s failing. Can you help diagnose the root cause?”
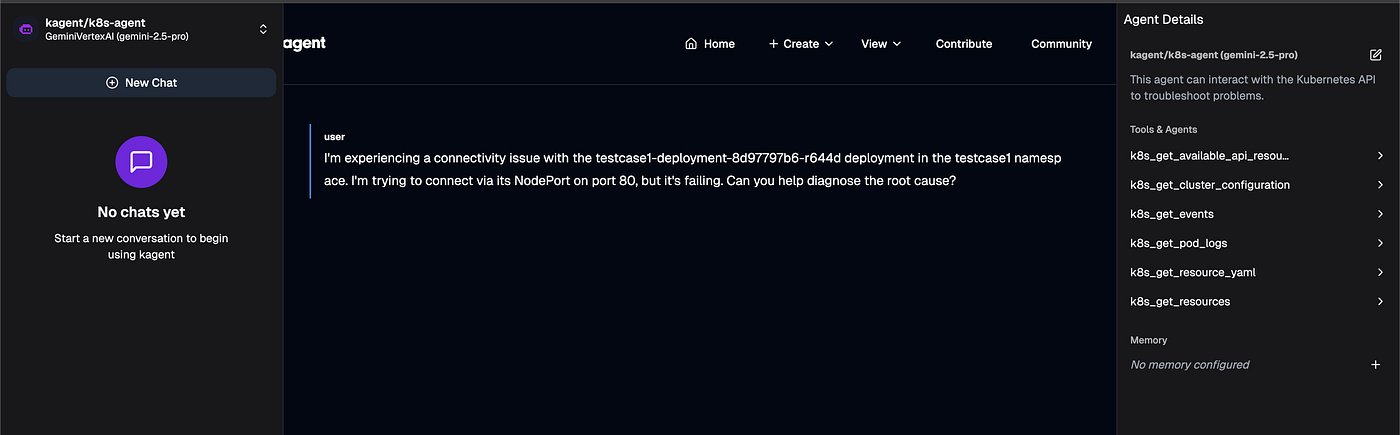
After receiving the prompt, the agent uses the tools it was granted to investigate the cluster state. It examines the pod, the service, and their configurations.

The agent then provides the following analysis:
The agent’s analysis is correct, as it successfully pinpoints the misconfigured targetPort as the root cause of the connectivity failure.
Scenario 2: Investigating a Resource Quota Failure
In our second scenario, we create a resource management issue. We have configured a namespace with a ResourceQuota that limits total CPU to 20m and memory to 20Mi. We then attempt to create a Deployment that requests 100m of CPU and 100Mi of memory, which exceeds the defined quota. We ask the agent to find out why no pods are being created:
”I’ve made some changes to the testcase2-deployment in the testcase2 namespace, and I’m not seeing any pods deployed. Can you investigate why?”
The agent investigates the deployment and the namespace and returns the following explanation:
Once again, a correct analysis from the agent. It accurately determined that the deployment’s resource requests were being denied because they exceeded the limits set by the namespace’s resource quota.
Scenario 3: Identifying an Image Pull Failure
For our final test, we introduce an ImagePullBackOff error. We configure a deployment to use an image tag that does not exist (nginx:1.29.2025-alpine), making it impossible for the cluster to pull the image and roll out the deployment. We then ask the agent for assistance:
”We’ve made recent changes to the testcase3-deployment in the testcase3 namespace, but the deployment isn’t rolling out as expected. Could you investigate why?”
The agent examines the deployment’s events and identifies the problem, providing a concise explanation:
The agent correctly identified the non-existent image tag as the reason for the deployment failure.
Analysis of the Results
In the three scenarios presented, the AI agent successfully diagnosed the root cause of each issue, providing clear and accurate explanations. It is important to note, that these tests were conducted in a controlled environment. Each problem was isolated within its own namespace, which simplifies the diagnostic process by limiting the scope of the investigation.
Furthermore, the prompts provided to the agent were intentionally specific. Our agent’s systemMessage encourages it to ask for clarification if a prompt is ambiguous, which is a desirable trait for collaborative problem-solving. To keep the examples in this post concise, we provided detailed prompts to get a direct answer. In a real-world scenario, an engineer might have a more interactive, conversational exchange with the agent to narrow down an issue, much like working with a human colleague.
Final Thoughts
The integration of AI agents into Kubernetes operations is a promising development, but it requires a thoughtful and cautious approach. While the potential for accelerating diagnostics and automating tasks is clear, several key considerations must be kept in mind.
- Security and Human Oversight: The principle of least privilege is essential. Starting with read-only tools, as we did in our setup, provides a necessary safety net. Any tool that can modify the cluster state should be introduced with extreme care and robust approval workflows. The AI should be treated as a capable assistant, but the ultimate authority and responsibility must remain with a human operator.
- The “Trust but Verify” Model: An AI agent’s output should be considered a highly informed suggestion, not an infallible command. Engineers must still use their judgment to verify the agent’s findings before taking remedial action, especially in complex or production environments where the risk of AI hallucination or misinterpretation exists.
- Configuration Complexity: The performance of an AI agent is highly dependent on its configuration. Choosing the right model, crafting a precise systemMessage, selecting the appropriate set of tools, and even formulating a clear user prompt are all critical decisions. An error or poor choice in any of these areas can lead to incorrect or unhelpful results, highlighting the importance of careful setup and testing.
- Quality of Interaction: The effectiveness of an AI agent is directly tied to the quality of the interaction. Clear, contextual prompts lead to better results. As these tools become more common, prompt engineering and the ability to have a clear, iterative dialogue with an AI will become valuable skills for operations teams.
- The Future is More Than Troubleshooting: While this post focused on diagnostics, the real value comes from expanding the agent’s capabilities. Proactive monitoring, automated remediation for well-understood issues, cost optimization analysis, and security auditing are all areas where AI agents could be very valuable in the future.
What are your thoughts on using AI for Kubernetes operations? Feel free to send any questions or feedback to stefan.pezzei@andamp.io.

Explore Our Latest Insights
Stay updated with our expert articles and tips.






Discuss Your Web Development Project with Our Experts Today.
Discover how our tailored web development solutions can elevate your business to new heights.
Stay Connected with Us
Follow us on social media for the latest insights and updates in the tech industry.