

In my humble opinion, most codebases suck. Programming is hard and there is too much creative freedom, leading to developers making bad decisions and causing inefficiencies everywhere.
And just like a writer suffering from writer’s block, we try to impose constraints on ourselves through architecture, by for example increasing the number of microservices and defining a single API through which they may communicate.
As a firm believer in the monolith-first approach, I find we can get a lot of mileage with less friction by simply structuring our monoliths better and constraining ourselves in other ways: if we are diligent about how side effects and state propagate through our code, we can write code that is a lot more maintainable and scalable.
Here’s what I’ve learned from spending many years in the trenches.
Code comes in three flavors
Any codebase can be split into three constituent parts: business logic, library code, and data.
Between the three parts, we can identify a dependency graph.
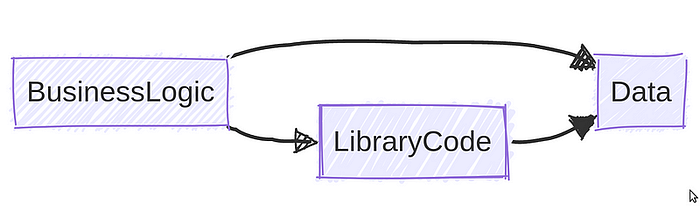
Data is all your plain old data classes, records, structs, etc., along with validation rules. Data classes are dumb and only hold information. They don’t know how to map themselves to another type, and in general, they can’t parse strings into themselves.
By library code, I mean code that is generic and reusable and can be taken and dropped into another project. Library code tends to be easily and thoroughly unit-testable because it’s usually not connected to your production database or coupled to your MVC framework. Library code should also strongly focus on developer experience because good DX allows you to iterate faster.
Business logic, then, is all the rest. It’s all the messy stuff that’s particular to your domain and the problem you are solving. Take every shortcut you need; we’ve all been there.
In bad codebases, you see too much happening on the business logic side, where, for example, low-level details about email transport are mixed with business rules that specify which email should be forwarded to which department.
The lower-level details should be abstracted away into library code, and the forwarding rules should be kept in business logic. Finding good abstractions is difficult of course, and a skill that one develops over time — Abstracting too early or too much is also an antipattern.
Before writing any class or piece of code, ask yourself which of the three bubbles it belongs to: Data, library code, or business logic. If you think it goes in business logic, ask yourself if you can separate meaningful library code from it.
Your primary goal should be to keep the business logic bubble as small as possible and the library code bubble as large as possible. Though of course, some projects are going to be very business-heavy and that’s okay, too.
Library code can also become very complicated, but you can split your library code into modules and structure those with the same approach. For example, say for your app you need to scrape hacker news so you write a HackerNewsScraper module that really should be perfectly reusable in another project. It will have plenty of library-type code (dealing with HTTP and parsing HTML), but it’ll have business logic of its own (the specifics of parsing the hacker news website).
A fractal structure emerges. Since fractals scale infinitely, our three-point approach works in any size codebase.
Also, note that I am not arguing for physically structuring your codebase into three modules. Library code and business logic can exist in the same folder or even file, distinguishing between the two is just a useful mental model.
State management
Library code should be the backbone of your application. We should strive to write it like our favorite libraries are written: Unopinionated, with few dependencies (= loosely coupled to the rest of the program), and with good DX (= simple API).
This often implies writing your library code as state-free as possible: A collection of pure functions is going to be easier to use than a collection of classes with difficult lifecycle management.
And, of course, pure code is more easily testable.
Code that is easy to unit test is also often easy to write and get correct (and easy to generate with LLMs). Knowing that you have a collection of code you can rely on means you can refactor your business logic more aggressively.
Write plain old functions that take everything they need as parameters and return all their results as the return value. If you need to keep state, see if a simple state machine pattern is sufficient before going for a class-heavy approach.
Side-effect management
Side effects are the root of all evil. Code that is side effect-free is usually trivially testable and, again, easy to reason about. Dealing with side effects is what makes programming hard.
Not all side effects are created equal — throwing exceptions, logging, and modifying arrays in place, for example, are very tame and often encouraged.
An HTTP server on the other hand brings in a swath of heavy side-effects like network I/O (malformed data, out-of-order requests) and high degrees of parallelism. Persisting data in a database is equally complicated.
These classes of side effects need to be well-managed, and isolated from the rest of the code base with airtight context boundaries. ORM users and redux users alike are encouraged to do database access everywhere because it is so easy to fetch data from persistent storage. As a result, developers do database access everywhere, leading to race conditions, caching issues, bad state-sharing patterns, and inefficient, hard-to-understand code.
When designing abstractions around heavy side effects, make sure to include some ceremony to add some friction to using them — this communicates via DX that these abstractions should be used with caution.
Library functions will inevitably need to perform effects, too; make sure those don’t happen on the side. By that I mean, when for example designing a generic DatabaseReader, make sure it only deals with a single class of side-effect (databases) and it clearly communicates to the developer that it does as such.
(Keeping state is also a side-effect, ranging from harmless to very complex.)
Functional core, object-oriented boundary
If our (unattainable) vision is to provide library code with no state and no side effects, this often lends itself to a functional approach.
By passing “dirty” things like database data into our library code via function parameters, we keep the core of our application pure, and have pushed all side effects to the edge of our program.
We also have effectively relegated OOP to deal with state and side-effect management, plumbing, and business logic, which is exactly what OOP is good at.
Locality of behavior
Code that acts together should be defined close together.
For example: If, to understand the business logic of a single service method call, it leads you across ten different files or services spread all over your codebase, it is likely due to bad design.
As another example, MVC frameworks have conditioned us to put all of our data classes into a “models” folder, but this is an antipattern. If you look at where any given model is used, it’s usually confined to a handful of classes. So, move the model with those classes into the same folder.
Moving tightly coupled code closer together physically will naturally result in a folder structure that resembles the call graph of your application, thus naturally segregating your code into meaningful, cohesive modules. This will help in finding better abstractions (=library code) suited to the sub-problem any given piece of code is solving. “Move things around until it feels right” is one of the better pieces of advice I have ever gotten.
Locality of behavior, much like single responsibility, is hard to get right, and often a matter of opinion. Any piece of code usually bridges two or more other pieces of code, meaning we have at least two places where it could be placed: Do we define all API routes in a controller, meaning the behavior we are describing is the HTTP server, or does each individual service define the API routes it is handling, meaning the behavior we are describing is the service? Here we would advise the former, but few decisions are so clear-cut.
Go forth and prosper
As always, critical judgement is more important than following dogma, and rules are meant to be broken. In my experience, worrying too much about project structure or side effects ain’t ever done no man no harm, but pragmatism and taking shortcuts will often lead to solutions better suited to your problem domain.
With this post, what I’m trying to do is bring side effects to the center of your attention while programming instead of them being an afterthought like they are for many of us. However, if you disagree with my points completely, be sure to let me know.
—
Here at &, we write code that is not only maintainable but also performant and pragmatic. Hire one of our teams of experienced engineers to design your app and ship it in a fixed time — no frills! (unless that’s what you like!)

Explore Our Latest Insights
Stay updated with our expert articles and tips.






Discuss Your Web Development Project with Our Experts Today.
Discover how our tailored web development solutions can elevate your business to new heights.
Stay Connected with Us
Follow us on social media for the latest insights and updates in the tech industry.